
I’m an AI researcher, architect, and entrepreneur. I’ve published extensively on the topic of machine learning and AI, including some of the most widely cited work in natural language processing of the last few years, made major initial contributions to the open source package Flair (now over 10,000 stars), was a driving force behind Zalando’s AI ramp up and NLP strategy, bootstrapped a 2-man startup LF1 to 7-figure revenue within 1.5 years, and exited the deep-learning powered e-commerce search suite Aleph-Search to the market leader in e-commerce search and navigation, Attraqt Group PLC.
If you are interested in working with me on a speculative project involving AI, deep-learning, natural language processing, semantic information retrieval or related areas, then please reach out with a short description of your idea and why the project is important to your company or organization. I’m potentially interested in full-time lead-research/ data-science roles which fit my interests, so drop me a line if you think you’ve got a good fit.
Here’s an up-to date traditional resume.
Education
- M.Math.Phil (1st class) in Mathematics and Philosophy from Oxford University, UK in 2007
- M.Sc in Computational Neuroscience and Machine Learning from the Bernstein Centre for Computational Neuroscience, Berlin, Germany in 2009
- Ph.D in Computer Science (Summa cum Laude) from the Technical University of Berlin, Germany in 2015
Employment
- Tutor for applied mathematics at African Institute for Mathematical Sciences, Bagamoyo, Tanzania (2015-2016)
- Postdoctoral researcher in Machine Learning and Statistics group at German Institute for Neurodegenerative Disease (DZNE) (Helmholtz), Bonn, Germany (2016-2017)
- Research scientist at Zalando Research in natural language and deep learning sub-group (2017-2018)
- Co-founder and CEO of LF1 as 33% equal share-holder (2019-)
- Independent AI researcher, entrepreneur and architect (2022-)
Publications
See my google scholar profile for an up-to-date record.
Projects
Aleph Search
Aleph Search is a complete suite for e-commerce search and navigation powered end-2-end with deep-learning, which I developed jointly with Alexander Schlegel as the first commercial project at LF1. Aleph Search was acquired by Attraqt Group PLC in 2020. I continued the journey with Attraqt in an advisory capacity until 2022, during which time Aleph Search (now Attraqt’s “AI powered search”) was deployed to production on the websites of the major e-commerce players in Europe. Among these are:
- Adidas
- Asos
- Missguided
- Pretty Little Thing
- Screwfix
- Secret Sales
- Superdry
- Waitrose

Aleph Search comprises:
- semantic search (search with “meaning”)
- similar product recommendation (search for similar “looking” products)
- reverse image-search (find a product using an uploaded image of worn fashion items)
- shop-the-look (find all items in an image containing multiple fashion items)
- auto-complete (suggest searches based on partial search)
- product tagging (fill out missing, or additonal product information)
Contextual string embeddings
In a research project together with Alan Akbik and Roland Vollgraf, we demonstrated in the first paper of its kind, that pretraining a high quality language model at the character level, leads to highly cost effective representations for named-entity recognition and general word-level sequence labelling tasks. Our analysis showed that character level language modelling combines the best of sub-word level granularity with meaningful semantic vectorial neighbourhoods for a number of downstream tasks. In languages such as German, which has a highly compositional structure from sub-word to word level, this leads to improvements over the SOTA of over 10%. The research paper was published and presented at COLING 2018, and made a major contribution to the proliferation of language model representations such as Bert, which form an integral part of e.g. the Google search algorithm.
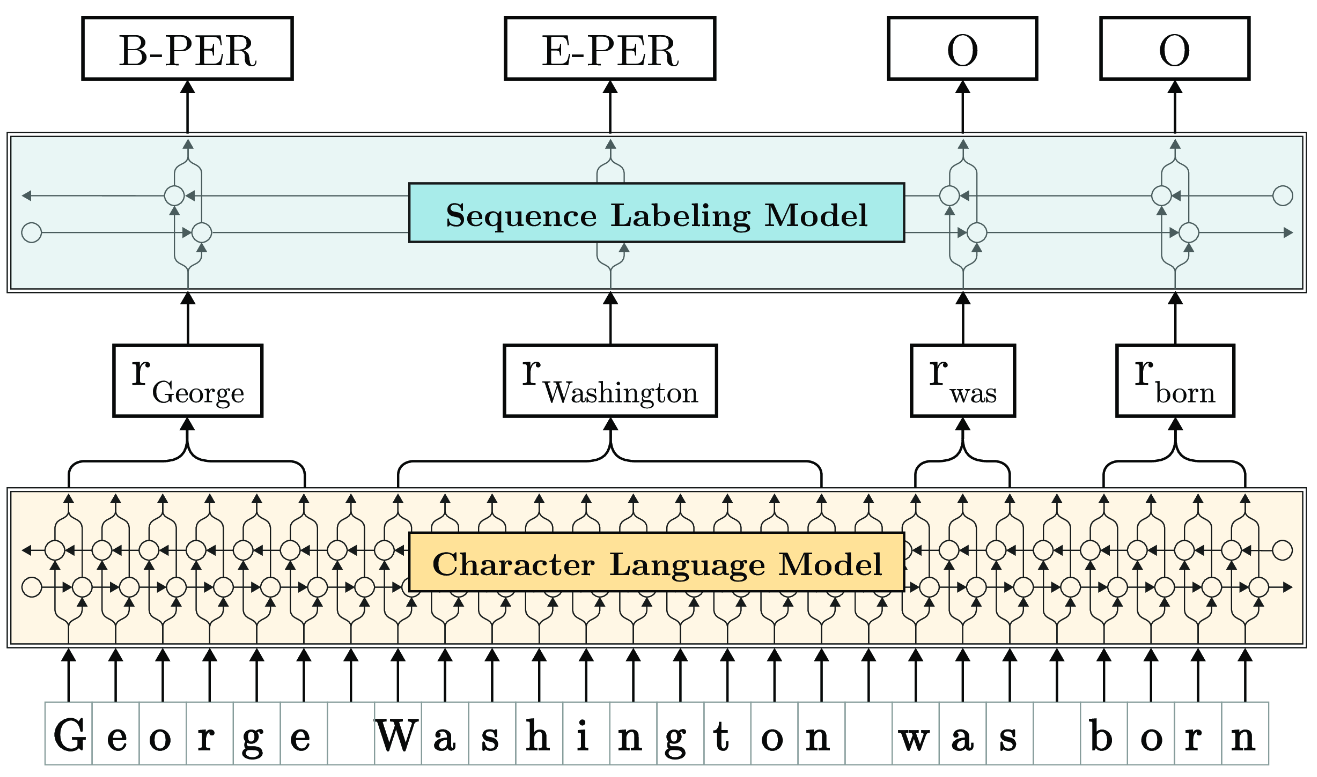
Flair

I was an initial contributor to the Flair library, an initiative of Alan Akbik (now Humboldt University) at Zalando Research. Flair is a simple but effective library for core NLP tasks, making it straightforward to deploy and combine word level embeddings for a variety of tasks, including:
- named entity recognition (NER)
- part-of-speech tagging (PoS)
- sense disambiguation
- sentence level classification
Sheen AI
I am technical advisor and co-developer of a recently launched venture Sheen AI. Sheen is a technology which transforms sound into visual art in real-time using AI, creating audio-reactive visuals as immersive, multi-sensory experiences.

PADL
Pipeline Abstractions for Deep Learning (PADL), codifies the approach we took to development at LF1 and is a project I initiated together with colleague and LF1 co-founder Alexander Schlegel.
Just as programs are read more often than they are written, so are deep learning models used more often than they are trained. The PyTorch ecosystem has many tools for training models. However, this is only the beginning of the journey. Once a model has been trained, it will be shared, and used in a multitude of contexts, often on a daily basis, in operations, evaluation, comparision and experimentation by data scientists. The use of the trained model, is how value is extracted out of its weights. Despite this important fact, support for using deep-learning models up to now has been very thin in the PyTorch ecosystem and beyond. PADL is a tool which fills this void.

Prediction and quantification of athletic performance
Together with Franz Kiraly, I developed and published a new approach to predicting and quantifying athletic performance, based on a novel combinatorial-matrix completion algorithm. The algorithm outperforms state-of-the-art approaches based on e.g. nuclear norm minimization as well as classic scoring methods such as the widely used “Riegel’s formula”. Integral to the approach is the assumption that distinct athletes weight short-distance, middle-distance and long-distance prowess relatively as a result of physiological make-up, training state and gender; the algorithm assesses these relative strengths through performance over a range of distances, and extrapolates to the desired distance by triangulating the athlete in a space of “prototypical” athletes.
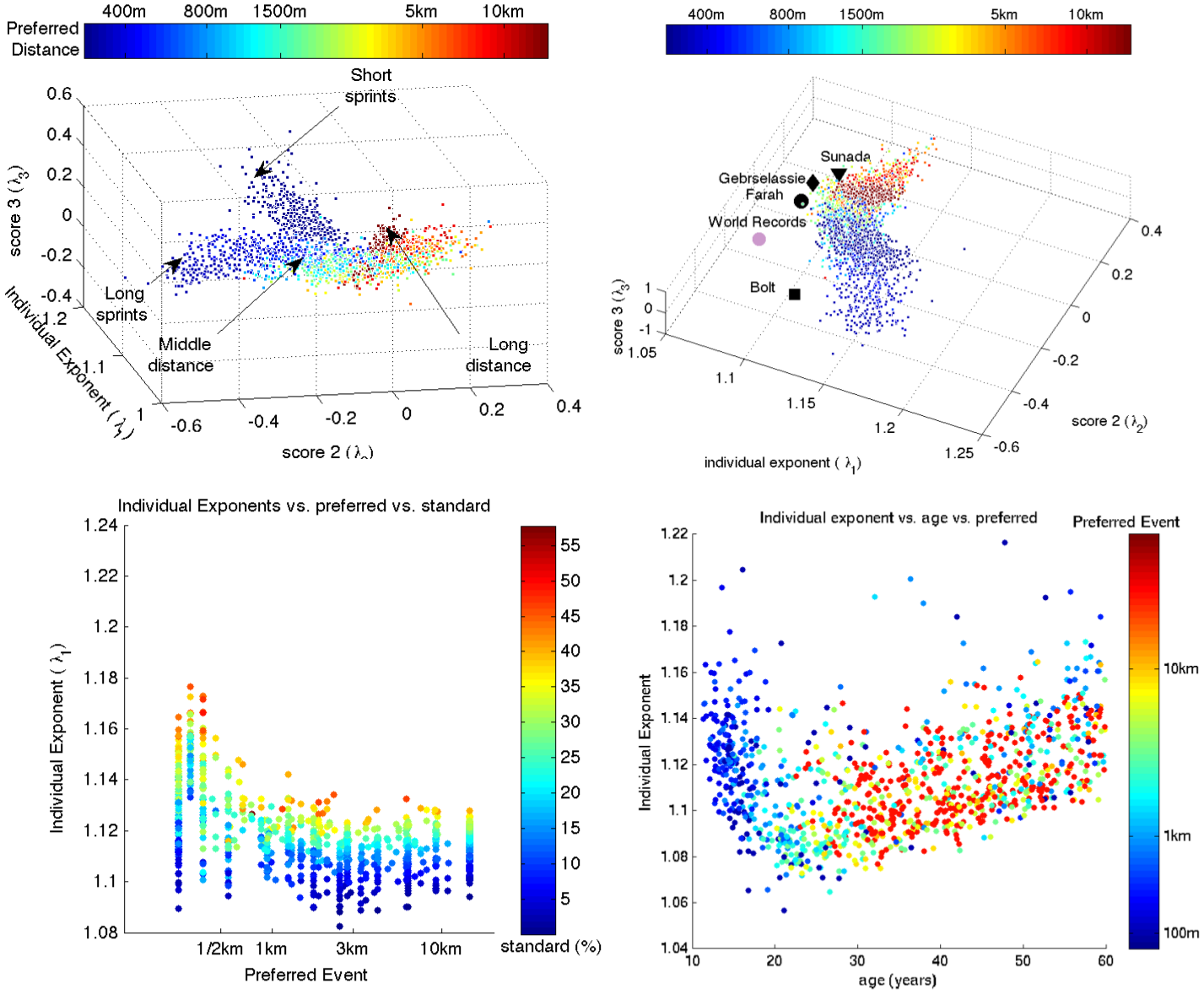
Current interests
At the moment I am interested in these things (among a great deal of other things):
- Latest NLP and deep-learning research.
- In data-base computation in the context of semantic information retrieval.
- Applications of deep-learning to Web3.
- MLops, particularly as regards pipelines taking models from research and experimentation all the way through to production.
Technology stack
- Python 2, 3
- PyTorch
- Tensorflow
- Git
- PostGreSQL
- MongoDB
- Flask
- AWS
- EC2
- Cloudformation
- s3
- IAM
- AutoScaling
- Docker
- Jenkins
- Javascript
- C/ C++
Machine learning stack
- Classical machine learning
- Kernel methods
- Source separation
- Clustering
- Dimension reduction
- Deep learning
- Convolution networks for vision (e.g. ResNet architectures)
- Deep ranking/ representation learning (e.g. Siamese network learning)
- Bounding box regression (e.g. Yolo architectures)
- Image segmentation (e.g. UNet)
- Language modelling (e.g. transformers and RNNs)
- Sequence-2-sequence learning (e.g. transformers and RNNs)
- Image generation with generative adversarial networks (e.g. StyleGAN+)
Useful links
- Google scholar profile
- GitHub profile
- Medium profile
- LinkedIn profile
- LF1 website
- PADL project website